Engineering Projects
Select projects demonstrating data engineering, system modernization, and performance optimization at scale.
Built a multi-agent RAG platform from scratch as the sole backend engineer, replacing a sunset third-party AI product and expanding beyond feature parity.
Problem
A partner AI product was being sunset, leaving a critical gap in Act-On's AI capabilities. The replacement needed to be built from scratch under a 3-month deadline with a single backend engineer.
What I Built
- •Multi-agent, multi-source RAG infrastructure using AWS Bedrock
- •Web crawler with Cloudflare bypass, auth handling, and distributed SQS-based processing
- •Async queuing system to prevent rate-limiting across concurrent crawlers
- •Many-to-many agent/source mapping — beyond the original one-to-one model
- •Delivered initial parity on the 3-month deadline, then expanded capabilities
Key Challenge
Ensuring consistent agent behavior across diverse customer configurations. Prompt tuning for one customer would break another — solved by building a systematic agent test framework that catches regressions before they hit production.
Impact
Replaced a third-party dependency with an in-house solution, reducing costs and giving full control over the AI product roadmap. Expanded beyond original feature parity to support many-to-many agent/source mapping.
Architecture Diagram
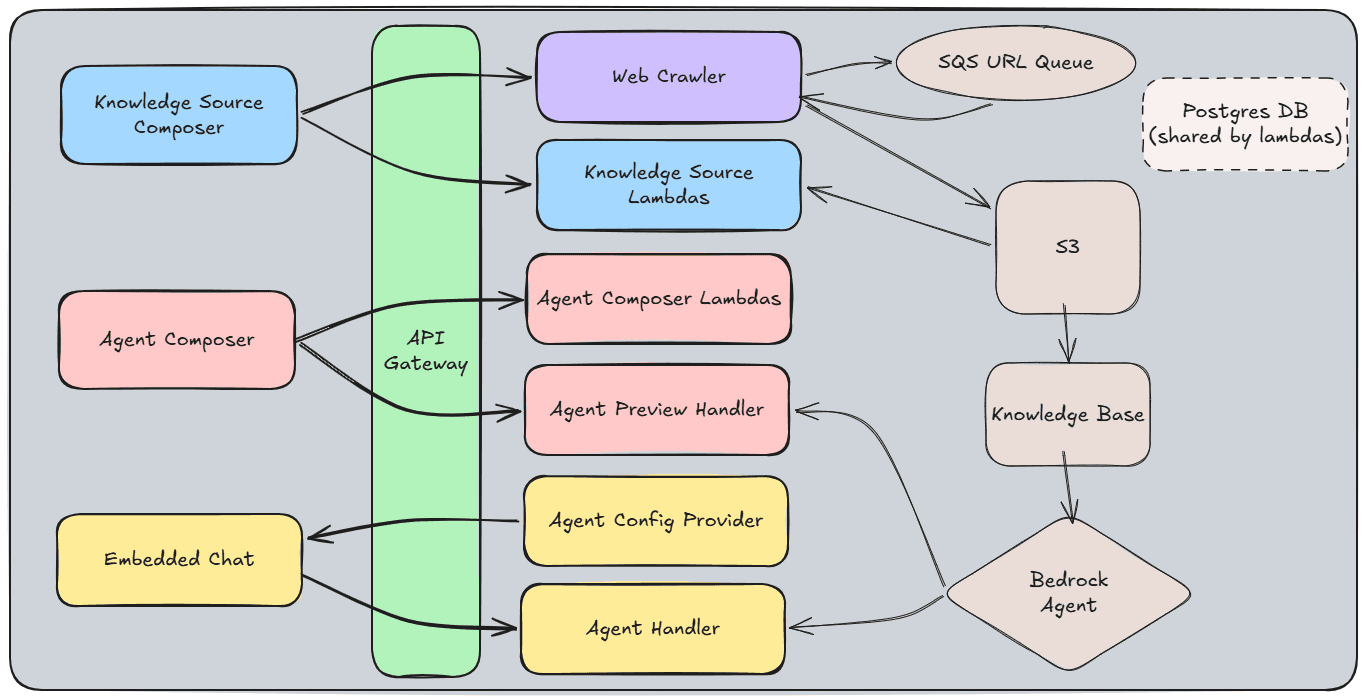
What I Would Do Differently
Use one language for the entire backend instead of splitting between Python and Node.js — two dependency ecosystems and two mental models added unnecessary friction. Invest more upfront in observability, since being the sole backend engineer means the system needs to tell you what's wrong. And engage the architecture committee earlier for peer review. The pressure to move fast meant I flew solo on architectural decisions that would have benefited from a second set of eyes.
Greenfield platform enabling customers to bring any structured data into Act-On for segmentation and personalized marketing — the most complex project I've worked on.
Problem
Act-On had no way for customers to integrate proprietary structured data — college grades, concert tickets, sales records — for segmentation and personalized marketing. Customers needed a schema-agnostic system that could handle arbitrary data shapes, both profile data (student records, contact info) and behavior data (event attendance, purchases), with both batch and real-time ingestion.
What I Built
- •Schema API supporting up to 512 columns with rich subtypes (URLs, custom enums, 40+ currencies, flexible date/datetime parsing)
- •Batch mode: S3 upload → ordered queue → SCDF job → validate/transform → Snowpipe Streaming → Snowflake staging → changeset detection → merge → Kafka
- •Streaming mode: Kafka topic (webhooks) → microbatch by account/object ID → same validation-through-merge pipeline
- •Per-row/per-column validation with detailed error reports (expected formats, fix suggestions, error codes mapped to logs for support)
- •Performance iterated from ~2 hours per 100K records to 1M records (52 columns, 1 GB) in under 10 minutes
Key Challenge
Date/datetime parsing without guaranteed format hints. Customers could provide dates in virtually any format, and the system had to figure it out — a deceptively hard problem at scale across dozens of locales and conventions.
Impact
Enabled Custom Objects — a new high-value product offering that gave customers the ability to bring any structured data into Act-On for segmentation and personalized campaigns. Opened new revenue streams and enhanced customer stickiness.
Architecture Diagram
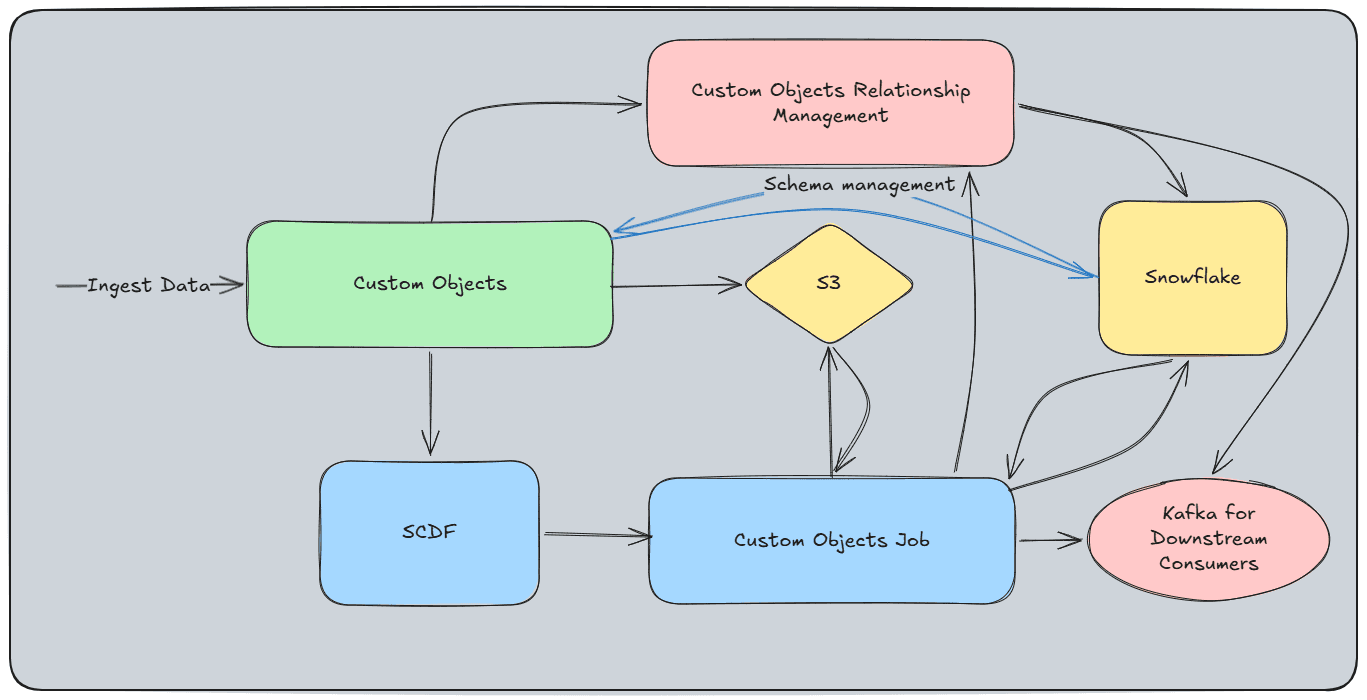
What I Would Do Differently
Store error report data in a database instead of S3. The current approach works for download, but makes it harder to display reports in-app and query across ingestion runs.
Traced a 'random' data duplication bug to its root cause in distributed H2 databases, then modernized the service from Java 8 to 21 with zero downtime.
Problem
A mission-critical dataflow service ran on each customer instance with embedded H2 databases storing read watermarks. It consumed 7 file-based data sources (fact data, CRM data, account data), transformed and published to Kinesis for 13 downstream dependencies. The distributed H2 instances caused silent data duplication — when a customer account migrated between instances, the target instance had no record of it and would re-read every piece of data from scratch. This was accepted as random duplicate data until I traced an escalation to a recent account migration and pieced the root cause together. The service was also stuck on Java 8 and was one of the most critical blockers for migrating from Flexential data centers to AWS.
What I Built
- •Diagnosed root cause: account migrations between customer instances caused full data re-reads (distributed H2 had no cross-instance awareness)
- •Upgraded Java 8 → Java 21 (required concurrent H2 version migration due to incompatibility)
- •Consolidated distributed H2 databases into centralized PostgreSQL using a dual-write strategy
- •Canary rollout: partial canary → full canary → incremental region-by-region
- •Updated Puppet and deployment pipeline for graceful rollout process
Key Challenge
The H2-to-PostgreSQL migration had to happen alongside the Java 8-to-21 upgrade because the embedded H2 version wasn't compatible with Java 21 — two tightly coupled migrations coordinated without breaking a service feeding 13 downstream dependencies.
Impact
Eliminated the silent data duplication that had been accepted as normal. Unblocked the Flexential-to-AWS cloud migration for this service — the most nuclear blocker, since without the fix, migrating would have duplicated all of every customer's data. Centralized data visibility replaced opaque per-instance H2 databases.
Architecture Diagram
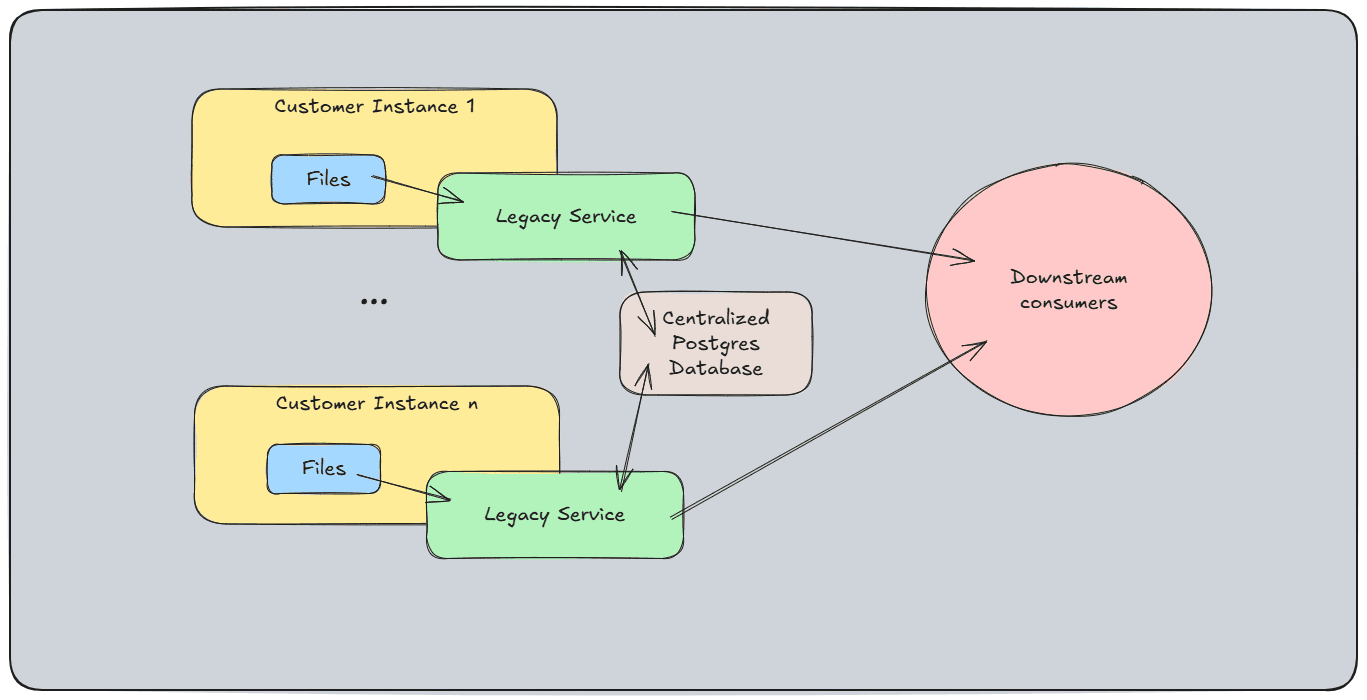
What I Would Do Differently
Put a microservice in front of PostgreSQL for watermark management instead of having ~100 customer instances connect to the database directly. The current setup works (I load-tested it before migration), but abstracting the database behind a service would be cleaner and more scalable.